Blog
Why the Size of AI’s Memory Changes Everything

A guide to context windows, token scale, and why your organization's AI future depends on what you structure today.
The Problem Nobody Is Talking About
You have probably already experienced this without knowing it had a name.
You open an AI tool, spend an hour building up context, explaining your project, walking through the background, getting to a point where the responses feel genuinely useful. Then you close the tab. The next day you come back and it is gone. The AI has no memory of what you discussed. You start again from scratch, summarizing everything you already covered, trying to get back to where you were. That summary itself consumes tokens. Your usage cap ticks down faster. You hit your limit before the work is done.
Or you stay in the same session, but it runs long. You notice the AI starts giving answers that feel slightly off. It references something correctly from the beginning of the conversation but seems to have lost track of a critical detail you added forty minutes in. It is not wrong exactly, just incomplete in a way that is hard to pin down. This is a well-documented phenomenon called lost-in-the-middle. AI models pay the most attention to what appears at the very start and the very end of their context window. Information in the middle, the part you built up over the course of a working session, tends to fade. The model does not forget it the way a person forgets. It simply weights it less.
These are not bugs. They are symptoms of a more fundamental constraint: the size of the AI's memory. And that constraint, more than any other factor, determines what AI can and cannot do for your organization.
Most productivity AI tools available today, including widely used products built on models like GPT-4o and earlier Claude versions, operate with context windows between 10,000 and 200,000 tokens. Even the current frontier models, ChatGPT running on GPT-4o and Claude Opus 4.6, top out at around 1 million tokens. That is genuinely impressive. It is also, as this post will show, only the beginning of what context scale makes possible.
This post explains what context windows are, why each order of magnitude matters qualitatively, not just quantitatively, and where we at Causal Dynamics Lab fit on that scale. We build causal AI. AI that reasons and connects throughout decades of knowledge in a single prompt. Our AI knows what’s being asked and filters out the noise to give everyone accurate results every time.
Context, Tokens, and Working Memory
Before we get into scale, it helps to understand the units.
A token is the basic unit an AI language model processes. Roughly speaking, one token equals about four characters of text, roughly three-quarters of a word. A 1,000-token context window holds around 750 words, or about two pages of a standard document.
The context window is everything the model can actively reason across in a single pass. Think of it as the AI's working memory: the desk it has to lay out all the documents it needs before it can start thinking. Everything on the desk is visible and connected. Everything off the desk might as well not exist.
Each 10× increase in context window size is not incremental. It changes what questions can even be asked.
This is the key insight the rest of this post is built on: context scale isn't a dial you turn up for marginal improvements. At each order of magnitude (10,000 tokens, 100,000, 1 million, and beyond), a qualitatively different class of problem becomes solvable for the first time.
Six Orders of Magnitude: What Each Tier Actually Unlocks
The following six tiers represent the major thresholds in context scale. At each level, we include the anatomy of that tier, what physically fits inside it, and the questions that only become answerable for the first time at that scale.
Pay attention not just to the numbers, but to the nature of the questions. They reveal something important about what kind of intelligence becomes available.
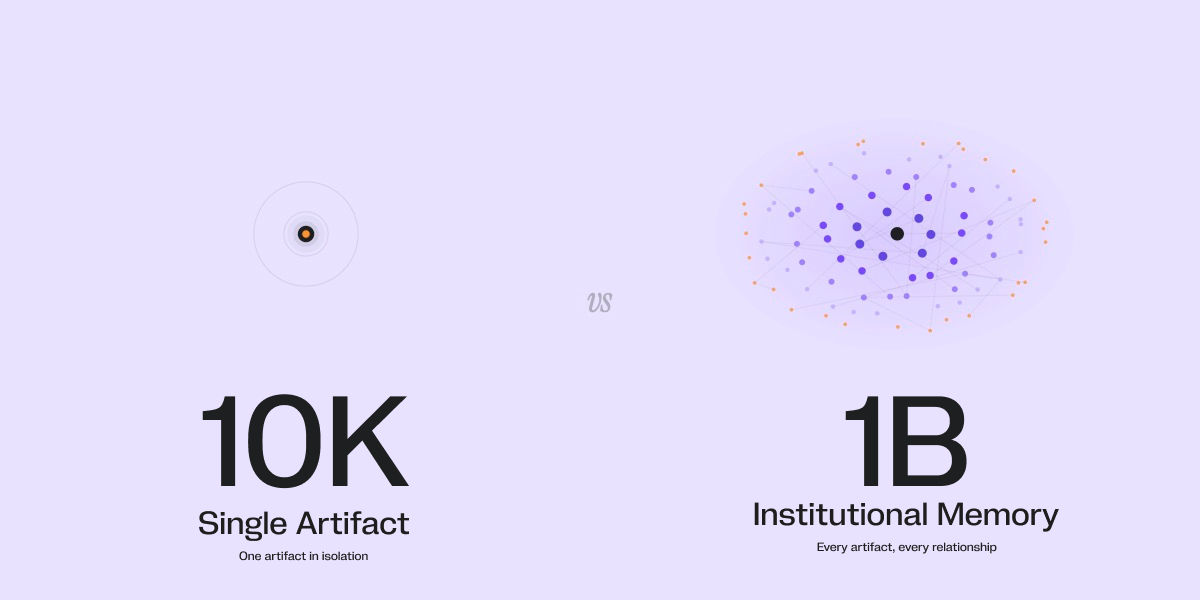
10K Tokens: Single Artifact
Think about what it is like to brief a new colleague on a meeting they missed. You hand them the transcript, they read it, and within minutes they can summarize the key decisions and flag any open questions. That is genuinely useful. But if you then hand them a second document from a different meeting and ask whether the two are consistent with each other, they would need to put the first one down, pick up the second, and hold both in memory at the same time. For most people, that is fine with two documents. At ten, it starts to slip. At a hundred, it becomes impossible.
A 10K context window is the AI equivalent of that colleague reading one document at a time. It can summarize, review, flag issues, and answer questions about whatever is in front of it. What it cannot do is tell you whether the document in front of it conflicts with the one you handed it twenty minutes ago. It has already let that go. This is where the vast majority of AI tools used in the workplace operate today, and for a great many tasks, it is exactly what you need.
At 10K tokens, the questions that become answerable reflect single-document work:
Strategic: “Summarize this meeting transcript and extract action items."
Security: "Does this file contain hardcoded secrets, API keys, or credentials?"
Developer: "Why is this function returning undefined intermittently?"
Every question here lives inside a single document. Hand the model one thing, get one answer. The moment a question requires comparing two documents, tracking a decision across a thread of files, or checking whether a promise made in one place was kept in another, you have stepped outside what this tier can see. That is not a criticism; it is simply the shape of the window.
100K Tokens: Cross Artifacts
Imagine you are preparing for a major contract negotiation and your team has produced a pile of documents over the past six weeks: the proposal, the legal terms, the technical specifications, the compliance checklist, three rounds of internal review notes. Each document made sense when it was written. Nobody sat down and compared them all together. At 100K tokens, the AI can hold all of it at once and read across every page simultaneously. It will find the sentence in the proposal that quietly contradicts a clause in the legal terms. It will notice that the compliance checklist marks a requirement as covered, while the underlying policy document says something different. It will catch what no individual reviewer caught, because no individual reviewer ever had all of it in front of them at the same time.
This is the first tier where the AI stops processing documents and starts auditing them. The difference matters. A processor handles one thing at a time. An auditor lays everything out and looks for what does not add up.
The questions that unlock here cross document boundaries for the first time:
Strategic: "Which sections of this RFP do our current capabilities not address?"
Security: "Map the authentication flow across this microservice and flag any unprotected endpoints."
Developer: "Are there race conditions in this service's concurrent paths?"
None of these questions could be asked at 10K. Each one requires the model to hold an entire set of related documents in view and reason about how they connect. That is not just more capacity. It is a different kind of thinking.
1M Tokens: Whole System
A million tokens is roughly the amount of knowledge one experienced person carries in their working memory across a career at a single organization. Every meeting they attended, every document they read, every decision they shaped, every lesson they absorbed from a failure. When you talk to that person, you are not asking them to search their memory for keywords. They reason from everything they know, simultaneously. Connections surface that they could not have predicted when they first encountered any single piece of the picture.
That is what a 1M context window gives an AI. The model is not searching an archive. It has read the whole thing and is reasoning across it. You can ask it about something buried in a contract from eight months ago and it will notice, without being prompted, that it conflicts with a commitment made in a completely separate document three months later. Nobody flagged the conflict at the time because nobody ever had both documents in front of them simultaneously. At this scale, the AI has read everything and forgotten nothing.
At 1M tokens, unknown-unknowns within a single system become discoverable:
Strategic: "Identify every regulatory commitment in our FDA submissions and verify compliance status."
Security: "Identify every service that talks to an external API without certificate pinning."
Developer: "Map cross-service dependencies and identify circular imports across the monorepo."
A skilled human expert could answer each of these questions in theory. In practice, it would take weeks of careful cross-referencing across hundreds of documents, and the honest answer is that most organizations never ask them at all, because the effort required has always outweighed the expected value. At 1M tokens, they become answerable in a single pass. This is the threshold where AI stops being a writing tool and becomes an analytical one.
10M Tokens: Year in Review
Most organizations have a version of this experience: something went wrong, and when the post-mortem happened, people realized the warning signs had been there for months. Not hidden, exactly. Just scattered. A flag raised in one team's incident report. A comment buried in a different department's audit log. A pattern in the support tickets that nobody had pulled together. Each signal, on its own, looked like noise. Together, they told a clear story. The problem was that nobody had all of them in view at once.
At 10M tokens, the AI can hold an entire year of an organization's operational life simultaneously: every report, incident log, meeting record, audit finding, and system change. It is not searching for a pattern you already suspect. It is reading across time and across teams and surfacing the thread that only becomes visible when all of it is in view at once. This is the tier where AI starts functioning less like a tool and more like an institutional conscience.
The questions at this scale reflect a new kind of institutional intelligence: pattern detection across time and divisions:
Strategic: "Across all business units, which controls have failed more than twice in the past 18 months and map to the same regulatory requirement?"
Security: "Identify every phishing report that mentioned a domain we later confirmed as malicious, including which users had clicked."
Developer: "Which on-call runbooks are stale relative to the systems they describe?"
Each of these questions involves connecting signals that were never in the same room at the same time. The control that failed in Q1 and the one that failed in Q3 were handled by different teams, logged in different systems, and reviewed by different people. No individual auditor ever saw both. At 10M tokens, the AI sees the full year at once, and the pattern that was invisible in any single quarter becomes obvious across all four.
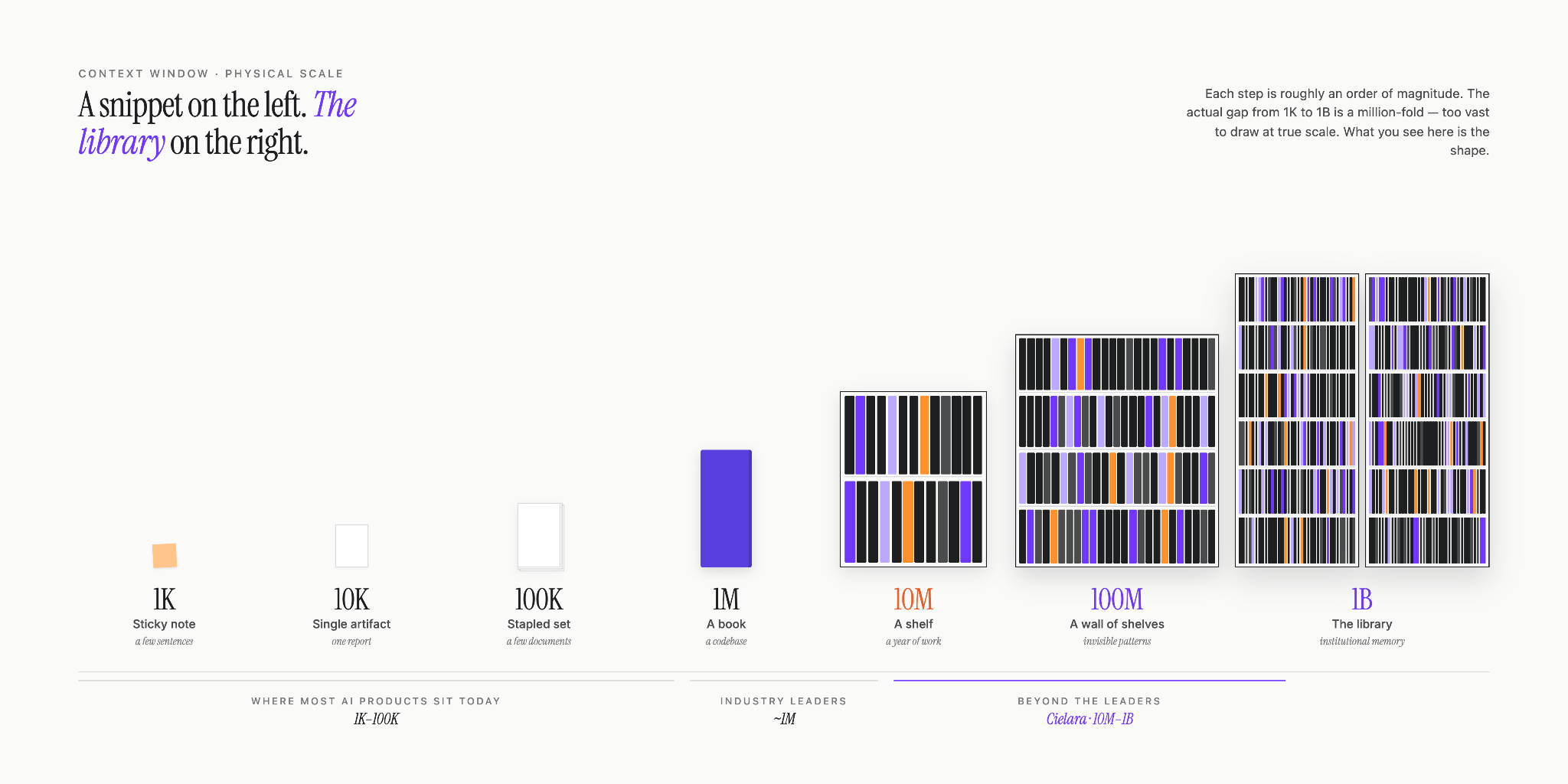
100M Tokens: Invisible Pattern Recognition
If 1M tokens is the knowledge one experienced person carries, then 100M tokens is the equivalent of having 100 people's worth of knowledge available simultaneously, and having all of it connected. Not 100 people you could interview one at a time. One mind that has absorbed the experience of all of them and can reason across everything they collectively know without losing the thread.
What this changes, practically, is the nature of the questions you can ask. At every tier below this one, you are asking the AI about something you already know to look for. You supply the question; it finds the answer. At 100M tokens, the AI can surface answers to questions you did not know you needed to ask. A pattern that exists in the relationships between documents, spread across a decade of communications, that no individual document contains and no search query would ever find. The insight is not buried. It is distributed across everything, invisible until everything is in view at once.
This is also where a widely used technique called RAG (which stands for Retrieval-Augmented Generation) starts to show its limits. Most enterprise AI today works by searching for relevant documents when you ask a question, then reasoning from what it retrieves. It is a practical and effective workaround when context windows are small, and it works well when you know what you are looking for. But you cannot search for what you do not know exists. The patterns that live between documents, the ones that only appear when everything is visible simultaneously, are precisely the ones RAG cannot find. At 100M tokens, native context reasoning reaches the problems that retrieval was never designed to solve.
The questions at 100M tokens reflect this shift. The answers live in aggregate patterns no human could manually reconstruct:
Strategic: "Does any warranty in the purchase agreement conflict with any document in the data room, across all 180,000 files?"
Security: "Identify all data-access patterns that, in aggregate, match an insider exfiltration profile, even where each event was individually approved."
Developer: "Identify all internal APIs whose contracts are technically broken by a downstream consumer but the break was never filed."
This is where we at Causal Dynamics Lab operate today. At 125 million tokens, we can hold and reason across a decade of an organization's knowledge in a single pass, without being told what to look for. Each of these questions represents the kind of analysis a skilled human team could theoretically undertake. In practice, it would require weeks of effort, precise advance knowledge of what to search for, and access to systems that were never designed to talk to each other. We do it without any of those preconditions. That is not a productivity improvement. It is a different category of capability.
1B Tokens: Institutional Memory
Every organization has knowledge that lives only in people. The engineer who remembers why a system was built the way it was, because they were in the room when the decision was made. The account manager who knows the history of a client relationship going back twelve years. The compliance officer who understands which regulatory interpretation the company adopted in 2014 and why it still shapes how they file today. When those people leave, that knowledge leaves with them. It does not live in any document, because nobody ever thought to write it all down in one place.
A billion tokens is roughly equivalent to the accumulated working knowledge of a thousand experienced people. At this scale, the AI does not assist an organization's memory. It becomes it. Every decision, every contract, every system, every failure, every supplier relationship, every regulatory filing across decades, held simultaneously and available for reasoning in real time. The question of what caused a production outage does not require pulling together six teams and three weeks of investigation. The question of which supplier dependencies create a cascading risk if a port closes on the other side of the world does not require a task force. These become questions with answers, asked and answered in the time it currently takes to schedule the meeting to discuss them.
The constraint at this tier is no longer the AI. It is the organization itself. The value of a billion-token context window is bounded entirely by how well an institution has structured and preserved what it knows. The organizations that are systematically building that foundation today are the ones that will operate at this scale first.
The questions here are ones no human team could answer through any manual process; they require holding an organization's entire existence in active reasoning:
Strategic: "If a magnitude-7.0 earthquake strikes Hualien tomorrow, which products production-stop within 72 hours, and what is our contractual exposure?"
Security: "Across all employee, contractor, and vendor records, identify combinations of access that no individual approver would have granted had they seen them together."
Developer: "Reconstruct the complete dependency graph (internal libs, services, vendor SDKs, OS packages) for every production system, at every release, over the program's lifetime."
This is the direction we are building toward at Causal Dynamics Lab. The capability already exists. What it requires is an organization that has done the work to make its knowledge available at that scale.
Where the Market Is and Where We Are Headed
The honest picture of the AI market today is this: most enterprise AI products operate in the 10K–100K token range. They are powerful tools for individual productivity: summarizing documents, drafting content, answering specific questions about a file. They are not yet capable of organizational-level reasoning.
The four strategic realities shaping what comes next:
We are already operating at 100M tokens, a scale at which we can reason across an entire decade of organizational output in a single pass. Most of our competitors are working with contexts 100 to 1,000 times smaller.
But our direction is 1B. Not because it is a number worth chasing, but because that is where the truly hard organizational questions live, the ones that currently have no human-scale answer.
The organizations that capture the most value from large context windows are not those with the most advanced AI. They are those who have systematically structured their institutional knowledge in machine-readable form.
The question for your organization is not whether large-context AI will become relevant to what you do. It will. The question is whether your information architecture will be ready when it does.
All AI abilities listed are accurate as of May 2026.
About the Authors
Emiliano Berenbaum is Field CTO Advisor at Causal Dynamics Lab, where three decades building identity, security, and machine-data infrastructure — including co-founding Scytale and engineering at Okta and Splunk — inform a practitioner's view of reasoning across systems at scale. He argues the real constraint on large-context AI is rarely the model; it's whether an organization has structured its knowledge to be machine-readable in the first place. Find him at https://www.linkedin.com/in/eberenb/
Eugene Weiss is a Member of Technical Staff at Causal Dynamics Lab, drawing on two decades of building AI and security systems — including the first deep-learning email threat detector to reach commercial production, built at Barracuda in 2016. He thinks about context windows the way infrastructure people think about memory hierarchies: a scarce resource whose structure determines what kinds of reasoning are even possible. Find him at linkedin.com/in/eugeneweiss
David Adil is a Technical Product Manager at Causal Dynamics Lab who specializes in turning data into stories that drive decisions. Bringing 7 years of experience across program management, product development, and human-centered strategy. He believes good leaders never stop learning, and the best leaders are measured by how much invest in the growth and encouragement the people around them. This shapes how he approaches AI: "a tool that sharpens human judgment, not one that replaces it." Find him at linkedin.com/in/daadil
Hasibul Haque is the CEO of Causal Dynamics Labs, an AI research lab building machines that reason through cause and effect rather than just predicting the next word. Before this he spent years in platform engineering, including a stint leading the function at Uber, which is partly where the conviction came from: AI’s worst habits (hallucinating with confidence, forgetting what it learned yesterday, wasting compute on context it doesn’t need) won’t get fixed by bolting a better explanation onto a black box. The reasoning has to be built in. Find him at linkedin.com/in/smhaque/
FAQ
Q. What's a token?
A A token is a measurement of data that AI uses to quantify what it's working with. 1 token is a four letter word like "book". The sentence "I read books" is turned into about 4 tokens. These tokens strung together allow AI to understand what you are asking it to do.
Q. Why does having a large context window help?
A. This is like the brain of AI. The larger the window, the more holistic an AI's response could be. For example, a 3 year old who makes a book is different than a 10 year old. Both could make a great picture book but the drawing ability, a written story, and the context of story will be more developed with the 10 year old since they know more about the world than a 3 year old. The 10 year old's context is multiple times larger than the 3 year olds.




